CLUSTERING FOR IMPROVED PLANNING & DESIGN
Very often spatial data has to be summarized in smaller sub-groups to perform efficient engineering.
This is always the case for many Cone Penetration Tests performed for road design, offshore wind farms and land reclamations.
Usually this is done on a subjective basis.
However, by using two techniques called Principal Component Analysis (PCA) and K-means clustering this can be done objectively.
This helps:
- Quickly mapping variability and clustering measurements at a site
- Improving time estimates and planning before and during project execution
- Reducing required effort to allow for efficient engineering and optimization
- Comparison of different sites during tender engineering for risk assessment
Disclaimer. Privacy. Unsubscribe. Reach out.
PRINCIPAL COMPONENT ANALYSIS
A jetty for vessel mooring has to be constructed at a site with varying soil conditions. Figure 1 displays all CPTs performed at the construction site of the jetty. From the variation in the soil behavior type index (Ic) it is already clear that the profiles vary. It is neither practical nor economical to account for each location individually in the design. Therefore a Prinicpal Component Analysis (PCA) is used for clustering. It reduces the amount of dimensions and simplifies the analysis without abstracting the variability too much. In this case the clustering is performed based on the classification index (Ic) over depth. After performing a PCA all locations can be plotted on a graph as visible in the Figure 2 below.
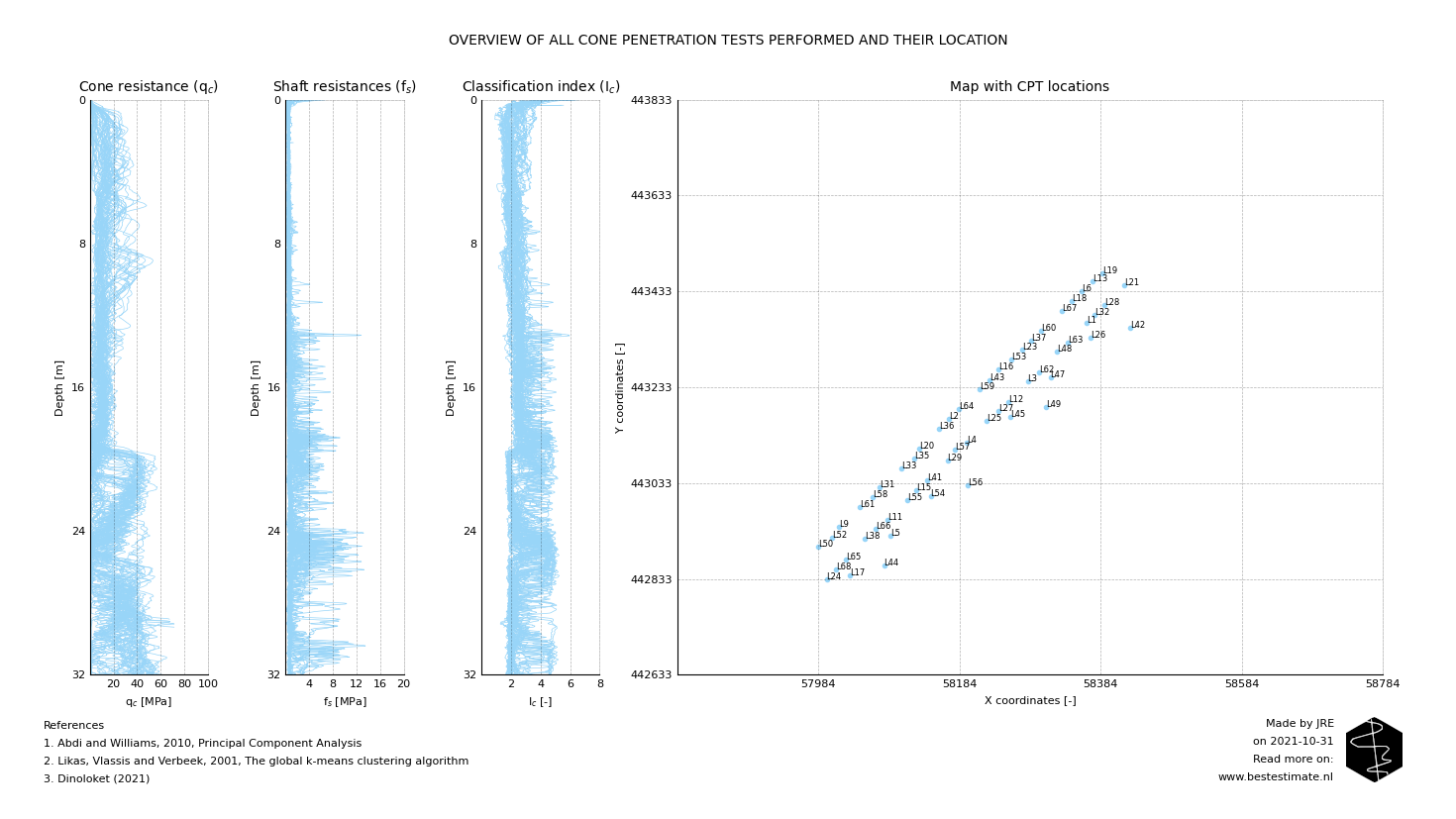
Figure 1, Overview of the location of all measurements and plot with all measured and computed data
Principal Component Analysis (PCA) is a relatively old technique in data science. It is a dimensionality reduction algorithm. In short it allows comparison of relatively complex measurements (like CPT tests) in an easy visual format. As a consequence easy comparison results in easy clustering.
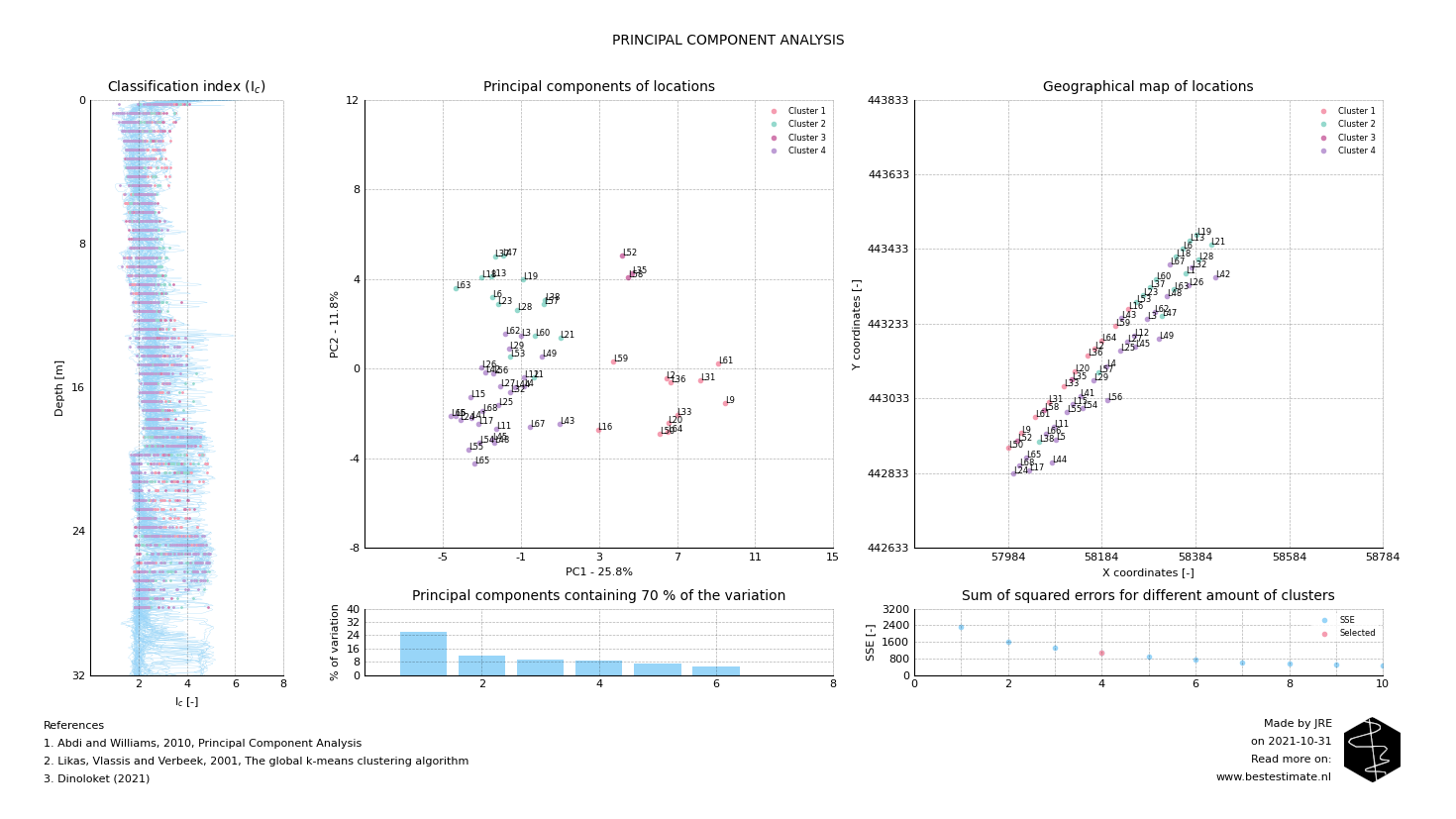
Figure 2, Overview of the results of the PCA. The closer the dots are together the more similar the two profiles are.
K-means clustering
The closer two points are together in Figure 2, the more similar these locations are. But that does not provide the clusters we need yet. K-means clustering is an automated tool which can be used to decide how much clusters are appropriate for the dataset considered. In this case four is a reasonable amount as observed from the 'elbow plot' in Figure 2. Of course a larger or smaller amount of clusters can also be used if desired. This is depends on how much the end user of the tool wants to optimize the design. The final results of the clustering analysis can be observed in Figure 3. Obvious differences can be observed between Cluster 1 and Cluster 4 beween 20 and 30 m below seabed. Based on thse 4 soil profiles the design can be continued.
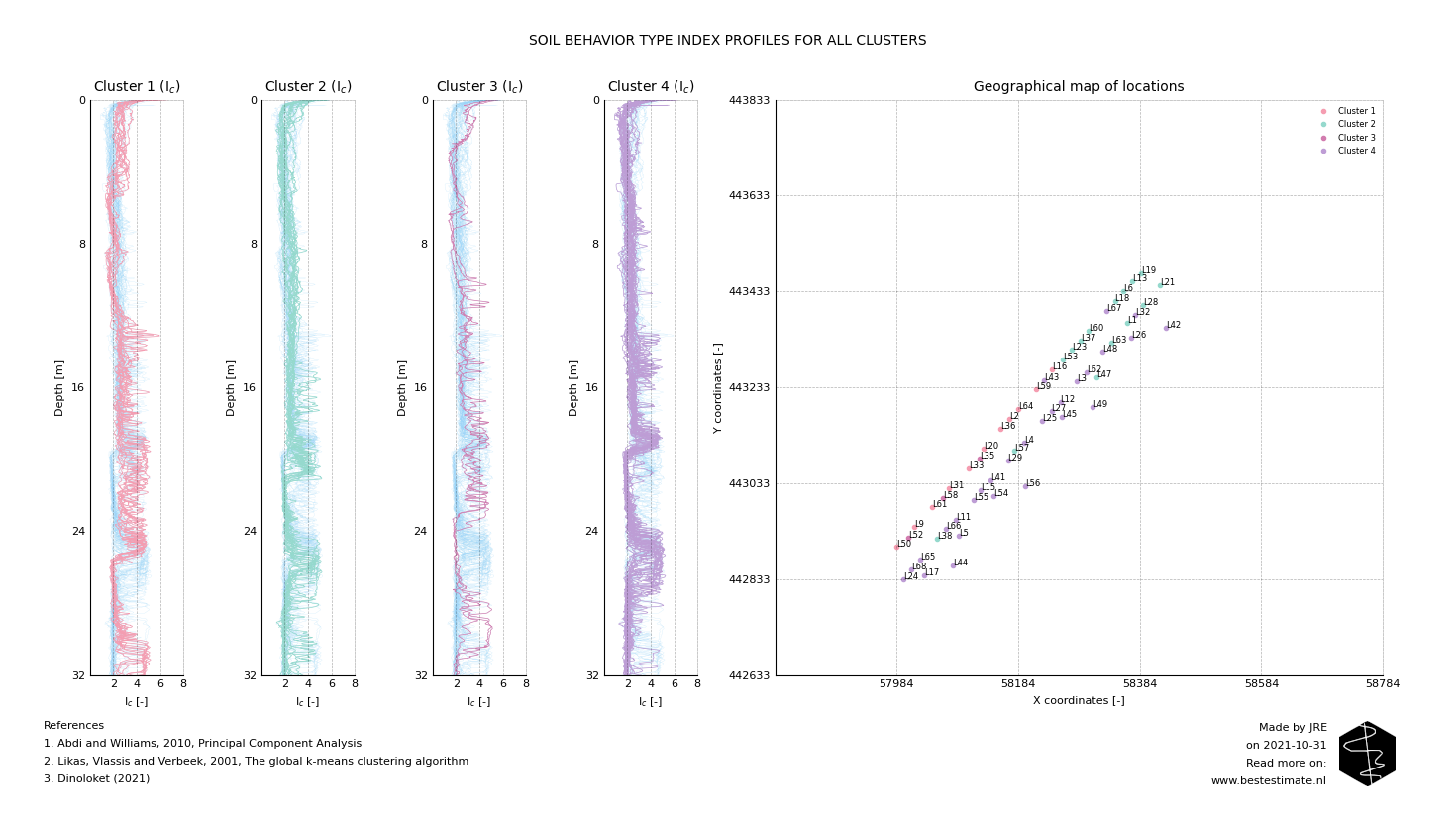
Figure 3, Four clusters obtained from PCA and K-means clustering
References
- Robertson, 2016, Cone penetration test (CPT)-based soil behaviour type (SBT)
- Abdi and Williams, 2010, Principal Component Analysis
- Likas, Vlassis and Verbeek, 2001, The global k-means clustering algorithm
- Dinoloket (2021)